There are two steps to creating your hierarchy data file:
1. Define the hierarchies - The best way to organize your data is to visualize it first, before you begin to structure it. This will allow you to decide the best way to structure your information and how many separate hierarchies are needed. To do so, draw out your hierarchies so that you can see their relationships.
2. Create the data file - You must have a specifically formatted data file to load the hierarchy. This file can be formatted horizontally or vertically, either with or without provision for case management.
The horizontal file format is simpler in its design and can often be the easiest way to manage a hierarchy if it will be maintained manually. However, this format does not support hierarchy structures when duplicate node names are required, such as nodes that need to repeat.
The vertical file format has more flexibility and data than the horizontal layout, and is considered a best practice when creating a hierarchy file. It is recommended that you use this format for programs that rely on complex hierarchy structures, including the following:
• Staggered interaction points that aren’t always at the same level but need to map to the same question in your survey;
• Nodes that need to be repeated across several levels, but must maintain the same name for reporting.
Rules for both formats:
1. All node IDs must be unique, but nodes can have the same name for reporting purposes.
2. All node IDs must roll up to only one parent ID.
The following sections provide more information on how to create each of the formats.
Step 1 - Define the Hierarchies
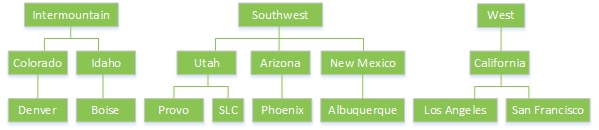
A helpful first step is to make an outline of the hierarchies you need to create. For our example, let's suppose that a hotel corporation wants to create the following hierarchies, united by the interaction point of the city in which the survey respondent's hotel is located:
• Brand
• State
• Region
For each of these hierarchies we want to create a collection of “nodes” underneath it. So, for example, let's suppose that we want the third hierarchy from our list above (Region) to look like this:
Note that the lowest level of this hierarchy is always a city. The lowest leaf in a hierarchy will be considered the “interaction point’ and the one that links to the survey. In our case, this corresponds to the answer to the survey question "Hotel location". In order for the hierarchy structure to map meaningfully to the survey it's linked to, there must be a question within the survey whose answers correspond exactly (including spelling and case) to all of the interaction points defined in the data file.
Now we sketch out our other two hierarchies, Brand and State, along similar lines, making sure that the lowest common denominator values (Interaction Points) are the same for those hierarchies.
The next step is to create the data file that will serve as the basis for the hierarchy structure. There are four different ways to create this data file – each of these can be downloaded with example data from the hierarchy admin tool in the platform (Surveys | Survey Hub | More | Hierarchy Management).
• Horizontally Formatted without Case Management (Download a Sample file-Simple)
• Horizontally Formatted with Case Management (Download a Sample file with Case Management-Simple)
• Vertically Formatted without Case Management (Download a Sample file-Advanced)
• Vertically Formatted with Case Management (Download a Sample file with Case Management-Advanced)
Note: For each of these data files, the column headers must appear in exactly the order described here. For logical and practical limits to the hierarchy data file, see that topic.
Here is a screenshot of a data file that exemplifies the horizontal format without case management:
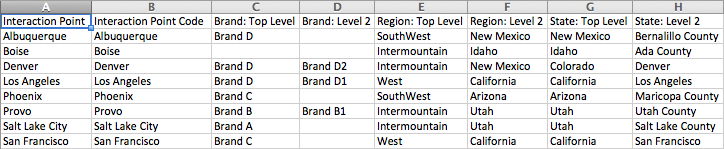
For a horizontally formatted file, each row in the table describes an interaction point: it defines all the hierarchies to which the interaction point belongs.
Note: In a given file, each Interaction Point Code (column B) must be unique: there cannot be duplicate Interaction Point Codes.
Each column describes attributes of a given interaction point. This example has the following column headers:
Interaction Point (column A) – This is the reporting-friendly name for your Interaction Point Code. Its column header must be "Interaction Point". For example, the Interaction Point Code could be a branch ID such as 4567, while the Interaction Point could be Denver.
Interaction Point Code (column B) – This is the lowest level of the hierarchy. Its column header must be "Interaction Point Code". The column should contain all possible answers to the question, and the text must exactly match what's in the survey.
Note: The survey question it is based on must be either a choose-one or text-as-category question.
Brand: Top Level, Brand: Level 2 - Node(s) in the first hierarchy. In our example, the first hierarchy (Brand) has 2 levels or nodes. The top level is hotel parent companies, e.g. Brand D, while the second level is hotel brands, e.g. Brand D1.
Note: The column header for the first column of the hierarchy must be formatted as "[top-level hierarchy name]: Top Level", e.g. "Brand: Top Level". The column header for the second column of the hierarchy must be formatted as "[top-level hierarchy name]: Level 2", e.g. "Brand: Level 2".
State: Top Level, State: Level 2, Region: Top Level, Region: Level 2 - Node(s) in the additional hierarchies. These follow the same format as that described above.
Note: The values in your file can be separated by commas, semicolons, or pipes, but not a mixture of these. Based on this selection, save your file as the appropriate type, such as .csv, .scsv, etc.
Here is the same hierarchy structure's data file, but with case management added:
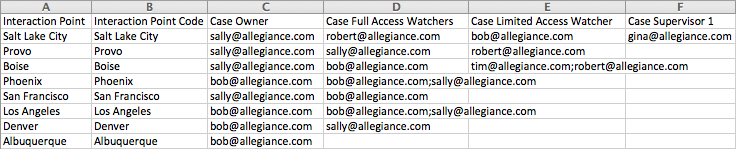
All of the same rules that apply to a horizontal file without case management also apply to one with it.
In this example, we see the same column headers as in the horizontally formatted file without case management. We also see these:
Case Owner, Case Full Access Watchers, Case Limited Access Watchers, Case Supervisor 1, 2, 3- These are role designations that are defined by the system. They determine the routing of your case:
• The Case Owner is the person responsible for taking action on the case and resolving it. There can only be one case owner.
• A Watcher is someone included in the email distribution list for the case who has read-only or greater rights on the case, but who is not primarily responsible for the resolution of the case - a Full Access Watcher can edit all fields on the case management page in the same way that the owner can; a Limited Access Watcher can add a case activity note and edit or remove their own notes.
• The Case Supervisor 1 is usually the Case Owner's manager; the Case Supervisor 2 is usually the Case Supervisor 1's manager, etc.
Notes: If you have multiple levels of case supervisor, you must define them according to this pattern: Case Supervisor 1; Case Supervisor 2; Case Supervisor 3. The columns Case Limited Access Watchers and Case Full Access Watchers are unique in that they can contain multiple users delimited by a comma, semicolon, or pipe. This must be the same delimiter used in the file overall.
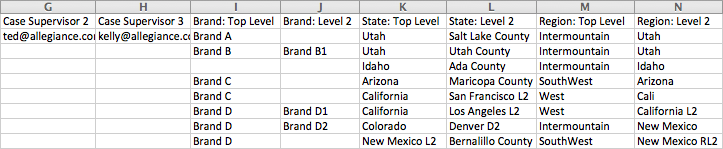
Here is the same hierarchy's data file, without case management and expressed in vertical format:
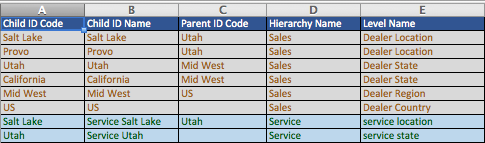
The same information used to create a horizontal hierarchy file is used in the vertical format, but all nodes (interaction points, mid-level, top level) have IDs as well as a name associated with them. In this file, each row in the table defines a node.
Child ID Code - Child ID Codes are unique identifiers for each node. When they are end nodes (interaction points) they must be the same as the survey answers to which you will link the hierarchy. When they refer to other nodes higher up the hierarchy, they are not linked to a survey question but instead refer to a point higher up the structure. You can list these nodes in any order, since each node is tied to a Parent ID Code.
Child ID Name - This is the name by which the node will appear in reporting. These are often more user-friendly descriptions of the node IDs, but they can also be identical to the values in column A.
Parent ID Code - Within a given row, the Parent ID Code specifies the node's next highest node up the hierarchy, its "parent". So, within the State hierarchy in our example, Salt Lake City's Parent ID Code is Salt Lake County, and Salt Lake County's Parent ID Code is Utah. The relationship between ID Codes and Parent ID Codes is the central logical link within the vertically formatted file: it is what defines the hierarchy.
Hierarchy Name - This is the name of the entire hierarchy. In our example our Hierarchy Names are Brand, State, and Region.
Level Name - This is the name of the node's level within the hierarchy. Level Name will eventually be used in reporting to look across a level in the hierarchy. This functionality is not currently supported by either horizontal or vertical files, but will be coming in Q4, 2015.
Here is the same hierarchy's data file, with case management and expressed in vertical format:

As with a horizontally formatted file with case management, this file has additional fields added to it. In the case of the vertically formatted file, they must be added on the far right of the file.
When you have finished defining your hierarchies, save your data file. You are now ready to upload it to the MaritzCX platform and link it to the desired survey(s) and survey question(s).